Modelling in space & time
Our researchers design methods to model and interpret patterns in data that change across time and space.

Staff
Postgraduate research students
Refine By
-
{{student.surname}} {{student.forename}}
{{student.surname}} {{student.forename}}
({{student.subject}})
{{student.title}}
Modelling in Space and Time - Example Research Projects
Information about postgraduate research opportunities and how to apply can be found on the Postgraduate Research Study page. Below is a selection of projects that could be undertaken with our group.
Evaluating probabilistic forecasts in high-dimensional settings (PhD)
Supervisors: Jethro Browell
Relevant research groups: Modelling in Space and Time, Computational Statistics, Applied Probability and Stochastic Processes
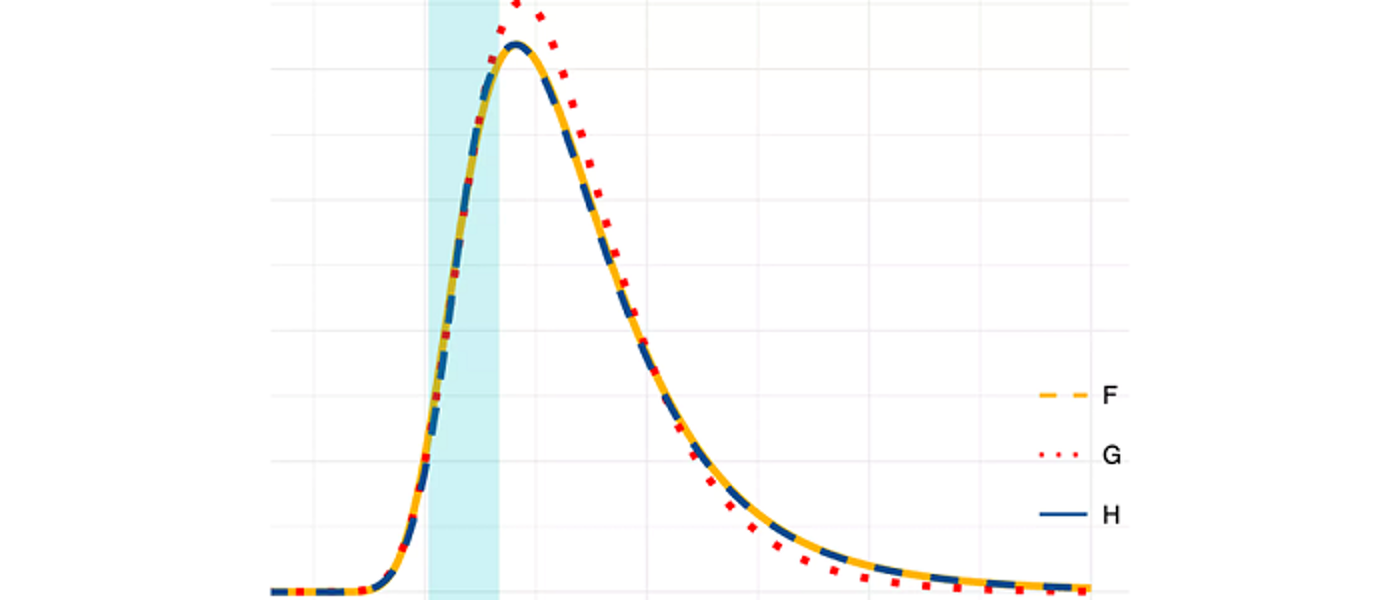
Many decisions are informed by forecasts, and almost all forecasts are uncertain to some degree. Probabilistic forecasts quantify uncertainty to help improve decision-making and are playing an important role in fields including weather forecasting, economics, energy, and public policy. Evaluating the quality of past forecasts is essential to give forecasters and forecast users confidence in their current predictions, and to compare the performance of forecasting systems.
While the principles of probabilistic forecast evaluation have been established over the past 15 years, most notably that of “sharpness subject to calibration/reliability”, we lack a complete toolkit for applying these principles in many situations, especially those that arise in high-dimensional settings. Furthermore, forecast evaluation must be interpretable by forecast users as well as expert forecasts, and assigning value to marginal improvements in forecast quality remains a challenge in many sectors.
This PhD will develop new statistical methods for probabilistic forecast evaluation considering some of the following issues:
- Verifying probabilistic calibration conditional on relevant covariates
- Skill scores for multivariate probabilistic forecasts where “ideal” performance is unknowable
- Assigning value to marginal forecast improvement though the convolution of utility functions and Murphey Diagrams
- Development of the concept of “anticipated verification” and “predicting the of uncertainty of future forecasts”
- Decomposing forecast misspecification (e.g. into spatial and temporal components)
- Evaluation of Conformal Predictions
Good knowledge of multivariate statistics is essential, prior knowledge of probabilistic forecasting and forecast evaluation would be an advantage.
Adaptive probabilistic forecasting (PhD)
Supervisors: Jethro Browell
Relevant research groups: Modelling in Space and Time, Computational Statistics, Applied Probability and Stochastic Processes
Data-driven predictive models depend on the representativeness of data used in model selection and estimation. However, many processes change over time meaning that recent data is more representative than old data. In this situation, predictive models should track these changes, which is the aim of “online” or “adaptive” algorithms. Furthermore, many users of forecasts require probabilistic forecasts, which quantify uncertainty, to inform their decision-making. Existing adaptive methods such as Recursive Least Squares, the Kalman Filter have been very successful for adaptive point forecasting, but adaptive probabilistic forecasting has received little attention. This PhD will develop methods for adaptive probabilistic forecasting from a theoretical perspective and with a view to apply these methods to problems in at least one application area to be determined.
In the context of adaptive probabilistic forecasting, this PhD may consider:
- Online estimation of Generalised Additive Models for Location Scale and Shape
- Online/adaptive (multivariate) time series prediction
- Online aggregation (of experts, or hierarchies)
A good knowledge of methods for time series analysis and regression is essential, familiarity with flexible regression (GAMs) and distributional regression (GAMLSS/quantile regression) would be an advantage.
The evolution of shape (PhD)
Supervisors: Vincent Macaulay
Relevant research groups: Bayesian Modelling and Inference, Modelling in Space and Time, Statistical Modelling for Biology, Genetics and *omics
Shapes of objects change in time. Organisms evolve and in the process change form: humans and chimpanzees derive from some common ancestor presumably different from either in shape. Designed objects are no different: an Art Deco tea pot from the 1920s might share some features with one from Ikea in 2010, but they are different. Mathematical models of evolution for certain data types, like the strings of As, Gs , Cs and Ts in our evolving DNA, are quite mature and allow us to learn about the relationships of the objects (their phylogeny or family tree), about the changes that happen to them in time (the evolutionary process) and about the ways objects were configured in the past (the ancestral states), by statistical techniques like phylogenetic analysis. Such techniques for shape data are still in their infancy. This project will develop novel statistical inference approaches (in a Bayesian context) for complex data objects, like functions, surfaces and shapes, using Gaussian-process models, with potential application in fields as diverse as language evolution, morphometrics and industrial design.
New methods for analysis of migratory navigation (PhD)
Supervisors: Janine Illian, Urška Demšar (University of St Andrews)
Relevant research groups: Modelling in Space and Time, Bayesian Modelling and Inference, Computational Statistics, Environmental, Ecological Sciences and Sustainability
Migratory birds travel annually across vast expanses of oceans and continents to reach their destination with incredible accuracy. How they are able to do this using only locally available cues is still not fully understood. Migratory navigation consists of two processes: birds either identify the direction in which to fly (compass orientation) or the location where they are at a specific moment in time (geographic positioning). One of the possible ways they do this is to use information from the Earth’s magnetic field in the so-called geomagnetic navigation (Mouritsen, 2018). While there is substantial evidence (both physiological and behavioural) that they do sense magnetic field (Deutschlander and Beason, 2014), we however still do not know exactly which of the components of the field they use for orientation or positioning. We also do not understand how rapid changes in the field affect movement behaviour.
There is a possibility that birds can sense these rapid large changes and that this may affect their navigational process. To study this, we need to link accurate data on Earth’s magnetic field with animal tracking data. This has only become possible very recently through new spatial data science advances: we developed the MagGeo tool, which links contemporaneous geomagnetic data from Swarm satellites of the European Space Agency with animal tracking data (Benitez Paez et al., 2021).
Linking geomagnetic data to animal tracking data however creates a highly-dimensional data set, which is difficult to explore. Typical analyses of contextual environmental information in ecology include representing contextual variables as co-variates in relatively simple statistical models (Brum Bastos et al., 2021), but this is not sufficient for studying detailed navigational behaviour. This project will analyse complex spatio-temporal data using computationally efficient statistical model fitting approches in a Bayesian context.
This project is fully based on open data to support reproducibility and open science. We will test our new methods by annotating publicly available bird tracking data (e.g. from repositories such as Movebank.org), using the open MagGeo tool and implementing our new methods as Free and Open Source Software (R/Python).
Integrated spatio-temporal modelling for environmental data (PhD)
Supervisors: Janine Illian, Peter Henrys (UKCEH)
Relevant research groups: Modelling in Space and Time, Bayesian Modelling and Inference, Computational Statistics, Environmental, Ecological Sciences and Sustainability
The last decade has seen a proliferation of environmental data with vast quantities of information available from various sources. This has been due to a number of different factors including: the advent of sensor technologies; the provision of remotely sensed data from both drones and satellites; and the explosion in citizen science initiatives. These data represent a step change in the resolution of available data across space and time - sensors can be streaming data at a resolution of seconds whereas citizen science observations can be in the hundreds of thousands.
Over the same period, the resources available for traditional field surveys have decreased dramatically whilst logistical issues (such as access to sites, ) have increased. This has severely impacted the ability for field survey campaigns to collect data at high spatial and temporal resolutions. It is exactly this sort of information that is required to fit models that can quantify and predict the spread of invasive species, for example.
Whilst we have seen an explosion of data across various sources, there is no single source that provides both the spatial and temporal intensity that may be required when fitting complex spatio-temporal models (cf invasive species example) - each has its own advantages and benefits in terms of information content. There is therefore potentially huge benefit in beginning together data from these different sources within a consistent framework to exploit the benefits each offers and to understand processes at unprecedented resolutions/scales that would be impossible to monitor.
Current approaches to combining data in this way are typically very bespoke and involve complex model structures that are not reusable outside of the particular application area. What is needed is an overarching generic methodological framework and associated software solutions to implement such analyses. Not only would such a framework provide the methodological basis to enable researchers to benefit from this big data revolution, but also the capability to change such analyses from being stand alone research projects in their own right, to more operational, standard analytical routines.
FInally, such dynamic, integrated analyses could feedback into data collection initiatives to ensure optimal allocation of effort for traditional surveys or optimal power management for sensor networks. The major step change being that this optimal allocation of effort is conditional on other data that is available. So, for example, given the coverage and intensity of the citizen science data, where should we optimally send our paid surveyors? The idea is that information is collected at times and locations that provide the greatest benefit in understanding the underpinning stochastic processes. These two major issues - integrated analyses and adaptive sampling - ensure that environmental monitoring is fit for purpose and scientists, policy and industry can benefit from the big data revolution.
This project will develop an integrated statistical modelling strategy that provides a single modelling framework for enabling quantification of ecosystem goods and services while accounting for the fundamental differences in different data streams. Data collected at different spatial resolutions can be used within the same model through projecting it into continuous space and projecting it back into the landscape level of interest. As a result, decisions can be made at the relevant spatial scale and uncertainty is propagated through, facilitating appropriate decision making.
Statistical methodology for assessing the impacts of offshore renewable developments on marine wildlife (PhD)
Supervisors: Janine Illian, Esther Jones (BIOSS), Adam Butler (BIOSS)
Relevant research groups: Modelling in Space and Time, Bayesian Modelling and Inference, Computational Statistics, Environmental, Ecological Sciences and Sustainability
Assessing the impacts of offshore renewable developments on marine wildlife is a critical component of the consenting process. A NERC-funded project, ECOWINGS, will provide a step-change in analysing predator-prey dynamics in the marine environment, collecting data across trophic levels against a backdrop of developing wind farms and climate change. Aerial survey and GPS data from multiple species of seabirds will be collected contemporaneously alongside prey data available over the whole water column from an automated surface vehicle and underwater drone.
These methods of data collection will generate 3D space and time profiles of predators and prey, creating a rich source of information and enormous potential for modelling and interrogation. The data present a unique opportunity for experimental design across a dynamic and changing marine ecosystem, which is heavily influenced by local and global anthropogenic activities. However, these data have complex intrinsic spatio-temporal properties, which are challenging to analyse. Significant statistical methods development could be achieved using this system as a case study, contributing to the scientific knowledge base not only in offshore renewables but more generally in the many circumstances where patchy ecological spatio-temporal data are available.
This PhD project will develop spatio-temporal modelling methodology that will allow user to anaylse these exciting - and complex - data sets and help inform our knowledge on the impact of off-shore renewable on wildlife.
Analysis of spatially correlated functional data objects (PhD)
Supervisors: Surajit Ray
Relevant research groups: Modelling in Space and Time, Computational Statistics, Nonparametric and Semi-parametric Statistics, Imaging, Image Processing and Image Analysis
Historically, functional data analysis techniques have widely been used to analyze traditional time series data, albeit from a different perspective. Of late, FDA techniques are increasingly being used in domains such as environmental science, where the data are spatio-temporal in nature and hence is it typical to consider such data as functional data where the functions are correlated in time or space. An example where modeling the dependencies is crucial is in analyzing remotely sensed data observed over a number of years across the surface of the earth, where each year forms a single functional data object. One might be interested in decomposing the overall variation across space and time and attribute it to covariates of interest. Another interesting class of data with dependence structure consists of weather data on several variables collected from balloons where the domain of the functions is a vertical strip in the atmosphere, and the data are spatially correlated. One of the challenges in such type of data is the problem of missingness, to address which one needs develop appropriate spatial smoothing techniques for spatially dependent functional data. There are also interesting design of experiment issues, as well as questions of data calibration to account for the variability in sensing instruments. Inspite of the research initiative in analyzing dependent functional data there are several unresolved problems, which the student will work on:
- robust statistical models for incorporating temporal and spatial dependencies in functional data
- developing reliable prediction and interpolation techniques for dependent functional data
- developing inferential framework for testing hypotheses related to simplified dependent structures
- analysing sparsely observed functional data by borrowing information from neighbours
- visualisation of data summaries associated with dependent functional data
- Clustering of functional data
Estimating the effects of air pollution on human health (PhD)
Supervisors: Duncan Lee
Relevant research groups: Modelling in Space and Time, Biostatistics, Epidemiology and Health Applications
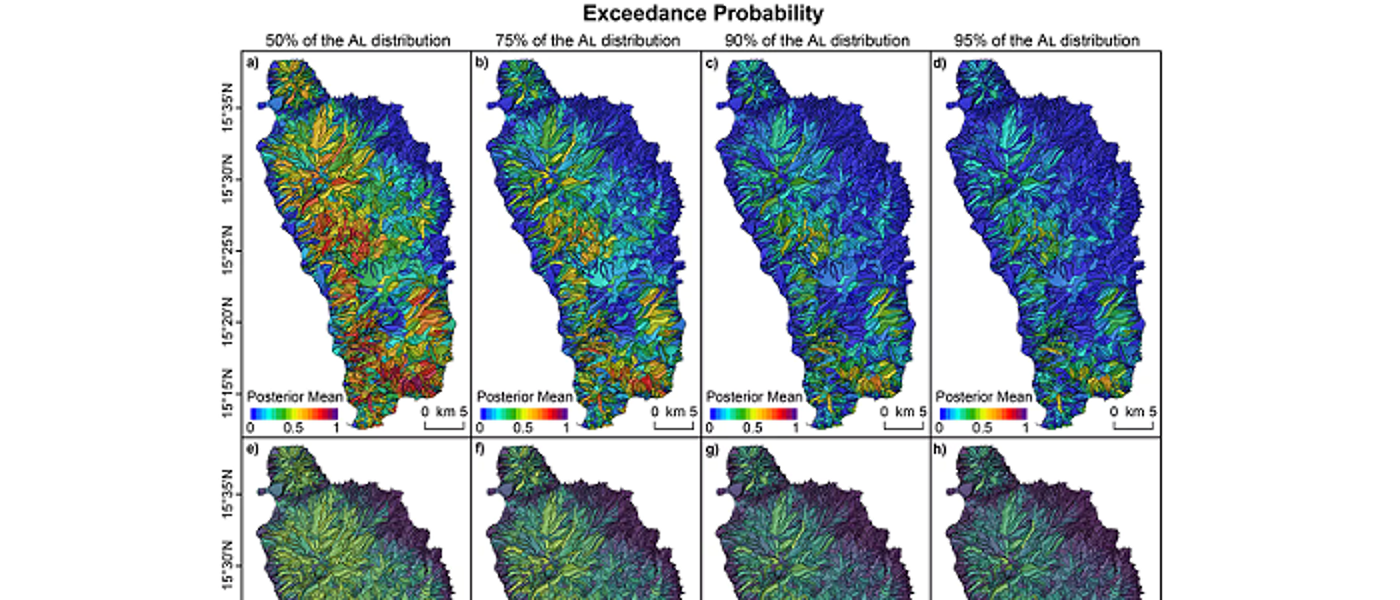
The health impact of exposure to air pollution is thought to reduce average life expectancy by six months, with an estimated equivalent health cost of 19 billion each year (from DEFRA). These effects have been estimated using statistical models, which quantify the impact on human health of exposure in both the short and the long term. However, the estimation of such effects is challenging, because individual level measures of health and pollution exposure are not available. Therefore, the majority of studies are conducted at the population level, and the resulting inference can only be made about the effects of pollution on overall population health. However, the data used in such studies are spatially misaligned, as the health data relate to extended areas such as cities or electoral wards, while the pollution concentrations are measured at individual locations. Furthermore, pollution monitors are typically located where concentrations are thought to be highest, known as preferential sampling, which is likely to result in overly high measurements being recorded. This project aims to develop statistical methodology to address these problems, and thus provide a less biased estimate of the effects of pollution on health than are currently produced.
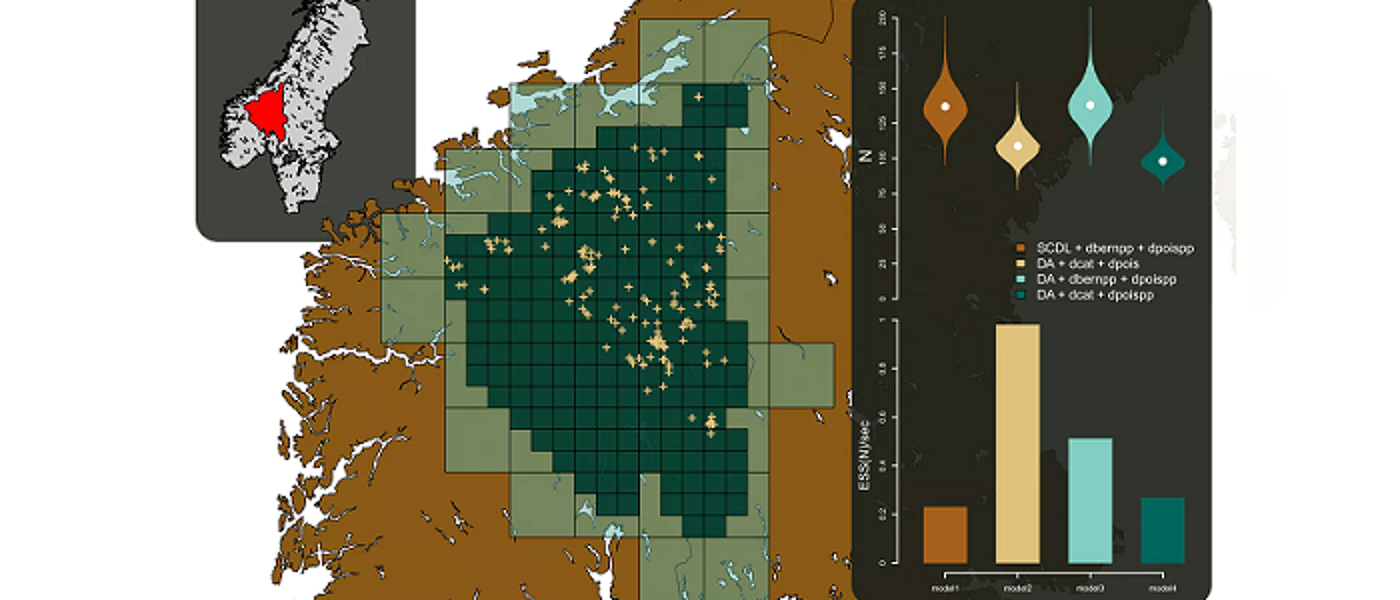
Mapping disease risk in space and time (PhD)
Supervisors: Duncan Lee
Relevant research groups: Modelling in Space and Time, Biostatistics, Epidemiology and Health Applications
Disease risk varies over space and time, due to similar variation in environmental exposures such as air pollution and risk inducing behaviours such as smoking. Modelling the spatio-temporal pattern in disease risk is known as disease mapping, and the aims are to: quantify the spatial pattern in disease risk to determine the extent of health inequalities, determine whether there has been any increase or reduction in the risk over time, identify the locations of clusters of areas at elevated risk, and quantify the impact of exposures, such as air pollution, on disease risk. I am working on all these related problems at present, and I have PhD projects in all these areas.
Bayesian Mixture Models for Spatio-Temporal Data (PhD)
Supervisors: Craig Anderson
Relevant research groups: Modelling in Space and Time, Bayesian Modelling and Inference, Biostatistics, Epidemiology and Health Applications
The prevalence of disease is typically not constant across space – instead the risk tends to vary from one region to another. Some of this variability may be down to environmental conditions, but many of them are driven by socio-economic differences between regions, with poorer regions tending to have worse health than wealthier regions. For example, within the the Greater Glasgow and Clyde region, where the World Health Organisation noted that life expectancy ranges from 54 in Calton to 82 in Lenzie, despite these areas being less than 10 miles apart. There is substantial value to health professionals and policymakers in identifying some of the causes behind these localised health inequalities.
Disease mapping is a field of statistical epidemiology which focuses on estimating the patterns of disease risk across a geographical region. The main goal of such mapping is typically to identify regions of high disease risk so that relevant public health interventions can be made. This project involves the development of statistical models which will enhance our understanding regional differences in the risk of suffering from major diseases by focusing on these localised health inequalities.
Standard Bayesian hierarchical models with a conditional autoregressive prior are frequently used for risk estimation in this context, but these models assume a smooth risk surface which is often not appropriate in practice. In reality, it will often be the case that different regions have vastly different risk profiles and require different data generating functions as a result.
In this work we propose a mixture model based approach which allows different sub-populations to be represented by different underlying statistical distributions within a single modelling framework. By integrating CAR models into mixture models, researchers can simultaneously account for spatial dependencies and identify distinct disease patterns within subpopulations.
Seminars
Regular seminars relevant to the group are held as part of the Statistics seminar series. The seminars cover various aspects across the AI3 initiative and usually span multiple groups. You can find more information on the Statistics seminar series page, where you can also subscribe to the seminar series calendar.
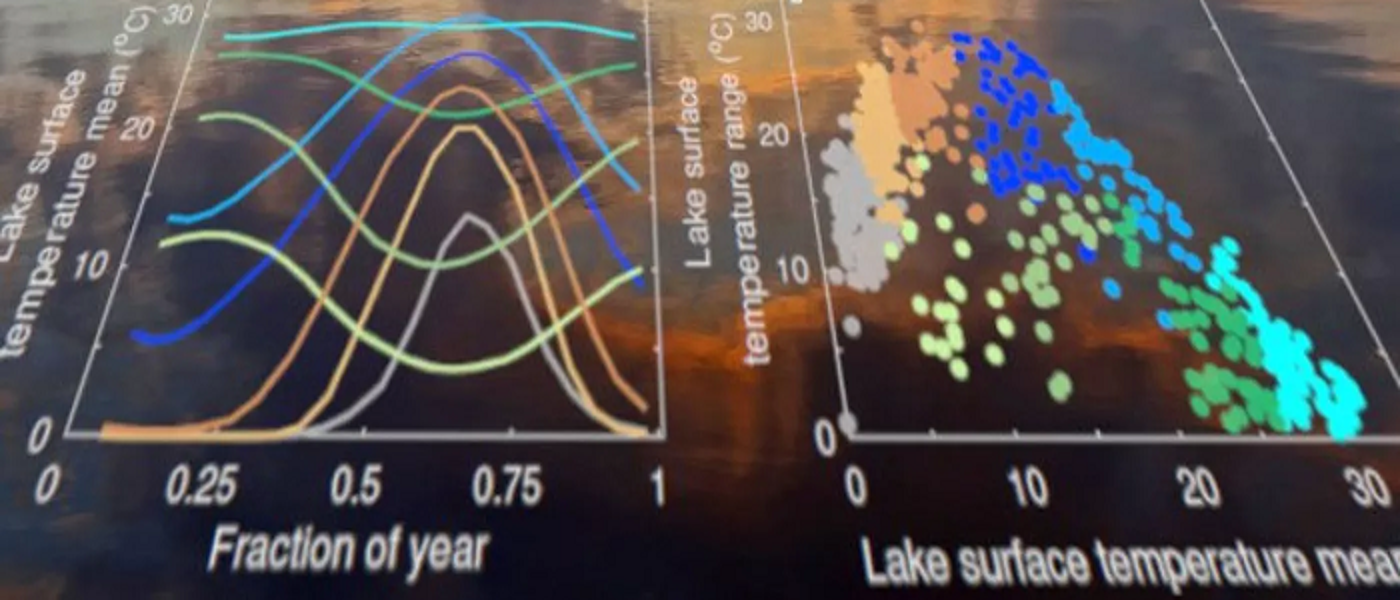
The main application areas the Modelling in Space and Time group work on include environmental, ecological and epidemiological contexts, where seasonal patterns, spatial hotspots and spatio-temporal correlations are all common data features. Collectively, the group develop novel methodologies that build upon state-of-the-art modelling approaches, including additive models, conditional autoregressive models, point process models and machine learning methods.
The group are also committed to reproducible research and open science, being the authors of widely used software packages in R such as CARBayesST and inlabru to allow others to implement the methods developed. With large active grants like GALLANT and active collaborations with the World Health Organisation, Public Health Scotland and industry leaders across a range of different industries, the group is one of the biggest in the school, with strong connections across multiple other research groups.