

Bayesian Model-Based Block Clustering
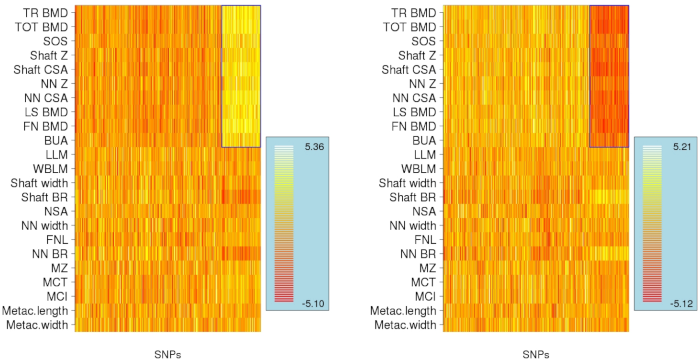
In large data matrices from many applications, it is often of interest to simultaneously cluster row and column variables, identifying local subgroups that share some common characteristic. When a small set of variables is believed to be associated with a set of responses, block clustering or biclustering can be a more appropriate technique to use compared to one-dimensional clustering. We have developed a flexible framework for Bayesian model-based block clustering, that can determine multiple block clusters in a data matrix through a novel and efficient population Monte Carlo-based methodology. On applying this to a genome-wide association dataset from the Framingham Osteoarthritis study, we found 2 distinct groups of genomic loci, one set positively, and one set negatively associated with a group of traits that are known to have an important role in susceptibility to bone fractures. Gene pathway analyses were able to map these to genes that are highly involved in structural development processes, indicating the potential for further biological insights.

Researchers
Publications
- An evolutionary Monte Carlo algorithm for Bayesian block clustering of data matrices, Computational Statistics and Data Analysis, 71 (2014)
- Identification of homogeneous genetic architecture of multiple genetically correlated traits by block clustering of genome‐wide associations, Journal of Bone and Mineral Research, 26 (6) (2011)
Organisations