

Closed-Loop Data Science
Partners
The project has a number of workpackages which give specifica application of closed-loop data science techniques to particular real-world problems:
WP1: Closed-loop interaction with probabilistic models
WP2: Closed-loop Data science and Pulmonary hypertension
WP2 B1 Recommender Systems and closed-loop feedback
WP2: Closed loop mass spectrometry measurement and analysis of metabolomics.
WP2: Closed-loop hearing aid optimisation
WP3: Intermittent Control in Data Science
WP3: Closed loop issues in Urban traffic control
WP1: Closed-loop interaction with probabilistic models
Evdoxia Taka, Sebastian Stein, John H. Williamson
Data science as practiced currently is an open-loop, statistician-controlled process: from a static dataset, models are learned and a subset of evaluation data is presented via fixed numerical and visual representations. There is limited scope for users to probe:
- whether a representation accurately captures domain knowledge;
- sensiivity to specific data points;
- uncertainty in predictions;
- or alternative causal explanations of the same observations.
We focus on Bayesian probabilistic inference, where analysis results in probability distributions over parameters (and potentially predicted outcomes). There is a narrow interface channel between users and the results of an inference process. We view the process as a closed-loop alignment of belief between users and inference results.
Why is this a closed-loop problem?
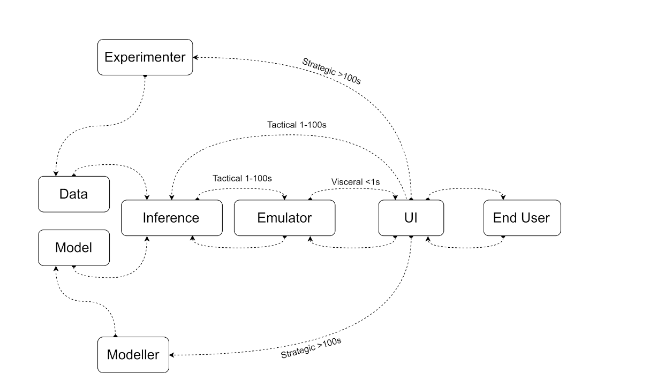
The closed-loop is between internal human belief states and probabilistic belief states implied by a model and dataset; the underlying hypothesis being that interactive control over the implications of a probabilistic model is required to effectively communicate it. Closing this loop becomes increasingly important as sophisticated models form the basis for human decision-making. We explore methods that support closed-loop interaction between user groups (statisticians, experimenters, domain experts and end users) that explicitly model and promote interaction with uncertainty.
This requires new processes and tools to turn static data into interactive systems; it requires modeling of predicted user interest; and latency-precision tradeoffs to maintain a stable flow of information. We view the problem as one of designing a closed-loop for performing synthetic experiments on the results of inference, and supporting users’ in making optimal experiments on belief distributions.
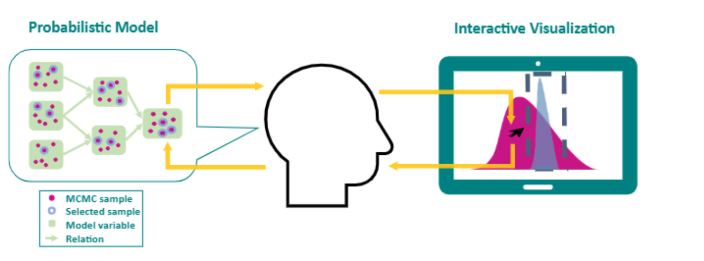
We focused on integrating interactive tools with standard MCMC-based probabilistic programming languages, with the vision of automatically generating interactive visualisations from a probabilistic program applied to a dataset.
WP1 Developments
We view the problem as one of alignment of human beliefs (mental models) and probabilistic insights (probability distributions, or samples from them). Our assumed inference process is that of an MCMC engine taking (priors, model, data) and producing (posterior, posterior_predictive) samples. The research problem is to take these components and “compile” them into a closed-loop system to align users’ beliefs with the inference output.
We have pursued this through the development of interactive systems to allow users to perform efficient experiments on the implications of a probabilistic inference engine. Latterly, we developed tools for causal exploration where these real-time synthetic experiments become explicit interventions in multiple structurally distinct probabilistic simulators fitted to a common dataset. In parallel, we have embedded interactive counterfactual analysis tools in a sequential human-controlled optimisation loop with our industrial partner Aegean, where probabilistic models suggest interventions via Bayesian optimisation.
Theoretical developments
- Closed-loop conditioning. The formulation and classification of visualisation and interaction techniques for interactive conditioning of probability distributions. WP1 focused on interactive conditioning on one or more marginal distributions as the primary method for closed-loop exploration of probabilistic models.
- Evaluation of probabilistic closed-loop visualisations. Development of robust evaluation protocols for interactive visualisations of probabilistic systems, including measures of rationality under utility functions as measured through simulated lotteries, and comprehension as measured by divergence between true and mental models.
- Simultaneous interactive causal interventions. Models of interactive exploration of a collection of competitive causal Bayesian models, using simultaneous synthetic interventions on probabilistic simulators trained on identical data.
Practical developments
- A visualisation platform for communication of Bayesian models with multiple univariate outcomes, including interactive conditioning, hypothetical outcome plots and smooth animated tours of conditional distributions.
- An interactive tool for comparative exploration of multiple causal explanations, based on MCMC sampling from multiple model structures trained on the same data, allowing a wide range of interactive interventions inside the model.
- A use case for interactive counterfactual analysis in a closed-loop human-controlled optimisation loop.
Each of these works with a standard probabilistic programming language (pymc3) and operates on a posterior trace and a skeleton model description.
Open questions
- User control (exploration) versus system control (recommendation). Our models close the loop between human beliefs and probabilistic estimates by affording control over conditioning. But we do not have an explicit model of what the human beliefs are. It remains to be explored how this could be used to optimise this alignment process. For example, a system that could recommend controls or offer partially automated tours of a posterior distribution could construct a more productive closed-loop.
- Model scale. Our models are capable of dealing with Bayesian problems of a realistic but moderate size. The problems of scaling up to “large” models with perhaps hundreds or thousands of latent parameters presents challenges in terms of computation, visualisation and cognitive constraints. Much of our work has focused on aligning intuitions about structural elements of Bayesian probabilistic models with their implications; closed-loop interactions can be effective here (e.g. in hierarchical models) but it is not clear how to tackle very deep hierarchies or very “wide” models with extensive latent variables.
- Extended hierarchy of control. We have focused on closing the loop between users and inference results as the most promising research direction. However, our original ambitions included closed-loops both at shorter timescales (using emulators to tilt the latency-precision tradeoff towards lower latency) and at longer timescales (closing the loop between inference consumers and the experiment design and data acquisition stages). These remain to be fully explored.
Publications
Taka, E., Stein, S., & Williamson, J. H. (2020). Increasing interpretability of Bayesian probabilistic programming models through interactive representations. Frontiers in Computer Science, 52.
Taka, E., Stein, S., & Williamson, J. H. (2022). Does Interacting Help Users Better Understand the Structure of Probabilistic Models? (under review/minor revisions). IEEE Transactions on Visualisation and Computer Graphics
Bin, M., Cheung, P., Crisostomi, E., Ferraro, P., Lhachemi, H., Murray-Smith, R., ... & Stone, L. (2020). On fast multi-shot COVID-19 interventions for post lock-down mitigation. arXiv preprint arXiv:2003.09930, 490.
Rusu, M. M., Schött, S. Y., Williamson, J. H., Schmidt, A., & Murray-Smith, R. (2022). Low‐Dimensional Embeddings for Interaction Design. Advanced Intelligent Systems, 4(2), 2100045.
Williamson, J. H., Quek, M., Popescu, I., Ramsay, A., & Murray-Smith, R. (2020). Efficient human-machine control with asymmetric marginal reliability input devices. Plos one, 15(6), e0233603.
Bach, E., Rogers, S., Williamson, J., & Rousu, J. (2021). Probabilistic framework for integration of mass spectrum and retention time information in small molecule identification. Bioinformatics, 37(12), 1724-1731.
Pre-prints
Stein, S., & Williamson, J. H. (2022). Evaluating Bayesian Model Visualisations. arXiv preprint arXiv:2201.03604.
Murray-Smith, R., Williamson, J. H., Ramsay, A., Tonolini, F., Rogers, S., & Loriette, A. (2021). Forward and Inverse models in HCI: Physical simulation and deep learning for inferring 3D finger pose. arXiv preprint arXiv:2109.03366.
Book chapters
Williamson, J. H. (2022). An Introduction to Bayesian Methods for Interaction Design. Bayesian Methods for Interaction and Design, 1.
WP2: Closed-loop Data science and Pulmonary hypertension
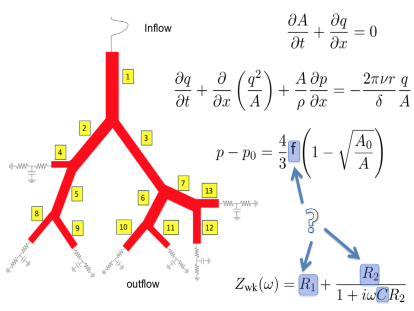
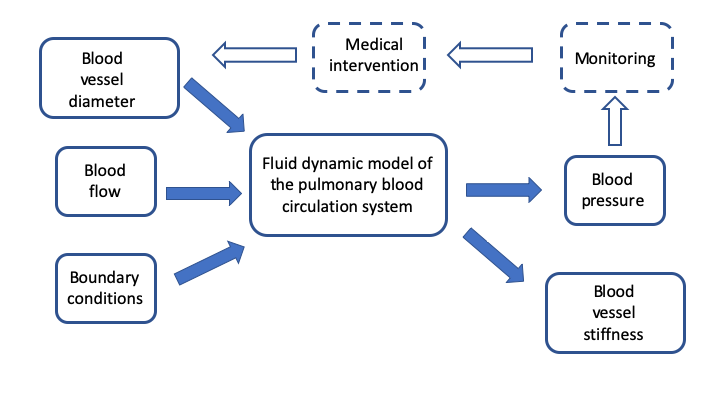
Publications
[10] Agnieszka Borowska, Diana Giurghita, and Dirk Husmeier. “Gaussian process enhanced semi-automatic approximate Bayesian computation: parameter inference in a stochastic differential equation system for chemotaxis”. In: Journal of Computational Physics 429 (2021), p. 109999.
[4] Agnieszka Borowska and Ruth King. “Semi-Complete Data Augmentation for Efficient State Space Model Fitting”. In: Journal of Computational and Graphical Statistics 32.1 (2023), pp. 19–35.
[5] Jon Devlin, Agnieszka Borowska, Dirk Husmeier, and John A Mackenzie. “Comparison and evaluation of ABC algorithms for inferring the drift-diffusion model parameters”. In: Subm. to Statistics and Computing (2022).
[6] Dirk Husmeier and L Mihaela Paun. “Closed-loop effects in cardiovascular clinical decision support”. In: Proceedings of the 2nd International Conference on Statistics: Theory and Applications (ICSTA’20). 128. 2020.
[8] Lukasz Romaszko, Agnieszka Borowska, Alan Lazarus, David Dalton, Colin Berry, Xiaoyu Luo, Dirk Husmeier, and Hao Gao. “Neural network-based left ventricle geometry prediction from CMR images with application in biomechanics”. In: Artificial Intelligence in Medicine 119 (2021), p. 102140.
WP2
Iadh Ounis, Craig Macdonald, Amir Jadidinejad, Sean Macaveny
Recommender systems are pervasive in daily life - such as in video on demand services exemplified by Netflix, shopping sites such as Amazon or search systems that recommend the best content for specific users. There are a plethora of machine learned models that can infer the latent preferences of users, and the properties of items, and use these to predict the next items (shows/produces/apps) that users are likely to interact with.
These learned models are typically trained, and evaluated, based on the items that users have interacted with in the past. However the users’ previous interaction behaviour can be affected by what items are being promoted to users by any already deployed recommender (aka item-selection bias). For instance, users may only interact with those items that they have been exposed to by the system. In this way, using historical interactions in the training and evaluation of a new recommender model, where those interactions have been obtained from the deployed recommender system, forms a closed feedback loop, i.e. the deployed recommender system has a direct effect on the collected feedback. The systems often also make use of an internal feedback loop in order to refine information needs or diversity results.
We pursued three primary directions in this work package, which are detailed below. We also enhanced our open-source tooling to facilitate this research.
Closed-loop Feedback in Recommendation and Search Data
Recommendation and search systems are often trained and evaluated based on feedback data that were collected from a deployed engine. This causes a feedback loop in which the recommender/search system and user are strongly connected in a dynamical system; each influences the other and their dynamics. Meanwhile, the output of this system is collected and used for training and evaluation of new systems.
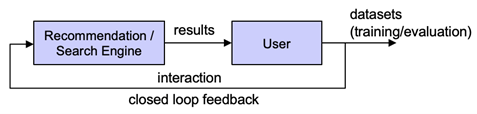
We quantified the effects of such closed loops; we found that they exacerbate the effects of popularity bias [1] and lead to Simpson’s Paradox during evaluation [5]. We then provided practical approaches for overcoming these problems through randomly opening the feedback loop [3] and propensity-based stratification during evaluation [5]. We also provided a new theoretical link between explicit and implicit feedback in recommender systems [2]. Further, we explored the presence of feedback loops in search datasets. Here, the set of queries is affected by survivorship bias, since those that the search system is unable to answer are discarded [14]. We quantified the effects of this closed loop on the training and evaluation of machine learning models and provided concrete suggestions on how to lessen the negative effects of such feedback loops when building datasets in the future [13,14].
Closed-loop Feedback in Proactive Search
Query strings entered into search engines often under-specify a user’s information need; query terms that could help identify the most relevant information may not be included for ease of writing, to fit into natural language, or simply because the terms themselves are what the user is looking to find. To overcome this, search engines often employ a feedback loop, wherein key terms from the top-scoring results are proactively fed back into the query in a process called pseudo relevance feedback. After one or more iteration of this process, the final results are presented to the user. This process creates closed-loop feedback because the retriever is affected by the results of the scorer.
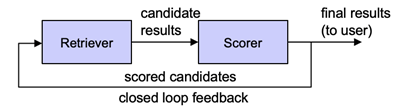
Previously, pseudo relevance feedback was limited to heuristic-based lexical matching systems. Through CLDS, we explored the application of learned retriever and scoring functions. Specifically, we found that the feedback mechanism can be applied to the latest dense retrieval methods [11,19], enhancing the precision and recall of search results. It is also effective when applied using external data for feedback in a zero-shot setting [20]. Further, we found that the feedback loop itself can be modelled as an information-seeking agent, which needs to decide whether to explore results from an initial candidate set or exploit the nearby documents of the top-scored results [15,16]. Finally, we explored approaches for automatically reformulating ambiguous queries, allowing the results to cover multiple potential information needs a user may have [6]. In all these formulations of result feedback loops, we find that the feedback loop enhances the results, identifying more relevant documents for user queries.
Closed-loop Feedback in Conversational Recommendation:
Conversational recommender systems (CRSs) have recently received much attention for addressing the information asymmetry problem in information seeking, owing to their flexible recommendation strategies and their natural multi-turn decision-making processes. In particular, a conversational recommender system is a type of recommender systems that can elicit the dynamic preferences of users and take actions based on their current needs through real-time multi-turn interactions. To this end, the conversational recommender systems can be generally considered to form closed loop systems in which the inputs (i.e. users' feedback) of the recommender systems are fully or partially determined by the outputs (i.e. recommended items).
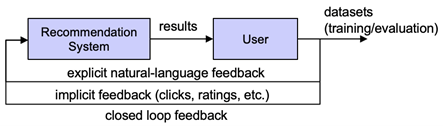
We started by modelling conversational recommendation as a partially observable Markov decision process, which we found can effectively address the [12]. We then further modelled the feedback loop as a recurrent attention network, which allow the re-introduction of user preference signals from previous natural-language feedback steps, further improving the quality of recommendations [21]. Finally, we studied the relative benefits of positive and negative conversational feedback, and found that positive feedback is more informative relating to the users' preferences in comparison to negative feedback [22]. These works further demonstrate how feedback loops can be beneficial in recommender systems and motivate continued work that focuses on positive feedback signals, rather than negative ones.
Tooling and Infrastructure:
To facilitate many these works, we enhanced our open-source Terrier engine. Specifically, new functionality was needed to support flexible retrieval pipelines (such as those containing feedback loops) [8], the latest efficient sparse retrieval methods [17], and evaluation measures that can measure qualities like search result diversity [18]. These efforts are widely recognised as valuable resources for the community and are increasingly used by other researchers worldwide.
References
[1] Amir H. Jadidinejad, Craig Macdonald, and Iadh Ounis. How sensitive is recommendation systems’ offline evaluation to popularity? In Workshop on Offline Evaluation for Recommender Systems at the 13th ACM Conference on Recommender Systems, 2019.
[2] Amir H. Jadidinejad, Craig Macdonald, and Iadh Ounis. Unifying explicit and implicit feedback for rating prediction and ranking recommendation tasks. In Proceedings of ICTIR, page 149–156. ACM, 2019.
[3] Amir H. Jadidinejad, Craig Macdonald, and Iadh Ounis. Using exploration to alleviate closed loop effects in recommender systems. In Proceedings of SIGIR, page 2025–2028, New York, NY, USA, 2020.
[4] Yaxiong Wu, Craig Macdonald, and Iadh Ounis. A hybrid conditional variational autoencoder model for personalized top-n recommendation. In Proceedings of ICTIR, page 89–96. ACM, 2020
[5] Amir H Jadidinejad, Craig Macdonald, and Iadh Ounis. The Simpson’s paradox in the offline evaluation of recommendation systems. ACM Transactions on Information Systems, 2021.
[6] Sean MacAvaney, Craig Macdonald, Roderick Murray-Smith, and Iadh Ounis. IntenT5: Search result diversification using causal language models. arXiv, abs/2108.04026, 2021.
[7] Craig Macdonald and Nicola Tonellotto. On approximate nearest neighbour selection for multi-stage dense retrieval. In Proceedings of CIKM. ACM, 2021.
[8] Craig Macdonald, Nicola Tonellotto, Sean MacAvaney, and Iadh Ounis. PyTerrier: Declarative experimentation in Python from BM25 to dense retrieval. In Proceedings of CIKM. ACM, 2021.
[9] Craig Macdonald, Nicola Tonellotto, and Iadh Ounis. On single and multiple representations in dense passage retrieval. In Proceedings of Italian IR Workshop. CEUR, 2021
[10] Nicola Tonellotto and Craig Macdonald. Query embedding pruning for dense retrieval. In Proceedings of CIKM. ACM, 2021.
[11] Xiao Wang, Craig Macdonald, Nicola Tonellotto, and Iadh Ounis. Pseudo-relevance feedback for multiple representation dense retrieval. In Proceedings of ICTIR. ACM, 2021.
[12] Yaxiong Wu, Craig Macdonald, and Iadh Ounis. Partially observable reinforcement learning for dialog-based inter-active recommendation. In Proceedings of RecSys. ACM, 2021
[13] MacAvaney, S. , Macdonald, C. and Ounis, I. (2022) Reproducing Personalised Session Search over the AOL Query Log. In: 44th European Conference on Information Retrieval (ECIR 2022), Stavanger, Norway, 10-14 Apr 2022, pp. 627-640.
[14] Gupta, P. and MacAvaney, S. (2022) On Survivorship Bias in MS MARCO. In: SIGIR 2022: 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11-15 Jul 2022, pp. 2214-2219.
[15] MacAvaney, S. , Tonellotto, N. and Macdonald, C. (2022) Adaptive Re-Ranking with a Corpus Graph. In: 31st ACM International Conference on Information and Knowledge Management (CIKM '22), Atlanta, Georgia, USA, 17-21 October 2022, pp. 1491-1500.
[16] MacAvaney, S. , Tonellotto, N. and Macdonald, C. (2022) Adaptive Re-Ranking as an Information-Seeking Agent. In: First Workshop on Proactive and Agent-Supported Information Retrieval (PASIR 2022), 17-21 October 2022, Atlanta , GA , USA.
[17] MacAvaney, S. and Macdonald, C. (2022) A Python Interface to PISA! In: SIGIR 2022: 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11-15 Jul 2022, pp. 3339-3344.
[18] MacAvaney, S. , Macdonald, C. and Ounis, I. (2022) Streamlining Evaluation with ir-measures. In: 44th European Conference on Information Retrieval (ECIR 2022), Stavanger, Norway, 10-14 Apr 2022, pp. 305-310.
[19] Wang, X., Macdonald, C. , Tonellotto, N. and Ounis, I. (2022) ColBERT-PRF: Semantic pseudo-relevance feedback for dense passage and document retrieval. ACM Transactions on the Web.
[20] Wang, X., Macdonald, C. and Ounis, I. (2022) Improving zero-shot retrieval using dense external expansion. Information Processing and Management, 59(5), 103026.
[21] Wu, Y., Macdonald, C., & Ounis, I. (2022, September). Multi-Modal Dialog State Tracking for Interactive Fashion Recommendation. In Proceedings of the 16th ACM Conference on Recommender Systems (pp. 124-133).
[22] Wu, Y., Macdonald, C., & Ounis, I. (2022, July). Multimodal Conversational Fashion Recommendation with Positive and Negative Natural-Language Feedback. In Proceedings of the 4th Conference on Conversational User Interfaces (pp. 1-10).
WP2: Closed loop mass spectrometry measurement and analysis of metabolomics
Metabolomics is the study of metabolites, small molecules that occur in all living organisms. Collecting and understanding metabolomics data is challenging. Data can be collected by putting a sample through a liquid chromatography Mass Spectrometry (LC-MS) system, in which the molecules present are first separated by the chromatography before being analysed by the mass spectrometer. The result is a series of (typically 1000s) of Mass Spectrometry scans, each of which records the mass to charge ratio and intensities of the metabolites present at a particular chromatographic retention time. Unfortunately, it is almost always impossible to identify molecule from their mass alone and it is therefore common to fragment metabolites via interleaving the normal MS scans with targeted MS/MS scans. Each MS/MS scan can provide information that can aid in the structural elucidation of one or more molecules. A key challenge when using mass spectrometry to collect and understand metabolomics data is choosing where and when to prioritise the MS/MS scans, while still maintaining enough normal MS scans be able to carry out basic data analysis. Acquiring improved data will benefit experiments, but it could be at the cost of missing something that would have otherwise been collected, potentially damaging experiments and trials.
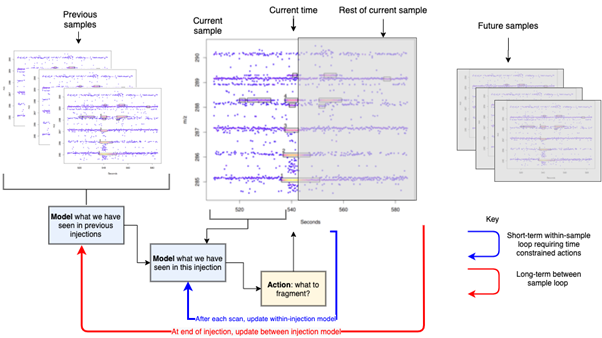
Closed loop issues become a problem when we attempt to make real-time intelligent decisions, rather than using pre-defined scan scheduling rules. When trying to make real-time closed loop decisions, two loops affect how we prioritise scans, as can be seen in the figure. Firstly, there is a short-term within sample loop (blue arrow), where we feedback the information gained from each scan in order to determine the best next scan type and location. Secondly, there is a loop where the results from previous sample are fed back into the decision process (red arrow), providing information which can help guide scan choices in future samples. Within this general measurement framework there are several inherent closed loop issues. The first is the finite scan budget: we have a limited number of scans and they cannot be done simultaneously. This must be done with only partially observed time series and with no knowledge of the success of our choices until after the completion of the sample (lagged reward). Within the second, outer loop we see issues with exploration vs exploitation, where we have the choice between confirming metabolites we think we know (exploitation) or attempting to fragment new, interesting metabolites (exploration). Balancing this trade-off well could lead to improved studies, while doing it badly could result in biased results which could invalidate entire studies.
Work has involved designing a framework which allows us to design controllers which can be used to control scans in real-time in both the Mass Spectrometer and in simulation [1]. Using this framework, new and improved controllers have been designed which have been shown to improve the number of metabolites fragmented [2] (inner loop). Current work is focused on how we can apply these methods across multiple samples and correct timing differences across samples in real-time to improve performance (outer loop).
Publications
[1] Wandy, J., Davies, V., JJ van der Hooft, J., Weidt, S., Daly, R., & Rogers, S. (2019). In silico optimization of mass spectrometry fragmentation strategies in metabolomics. Metabolites, 9(10), 219.
[2] Vinny Davies, Joe Wandy, Stefan Weidt, Justin JJ Van Der Hooft, Alice Miller, Rónán Daly, and Simon Rogers. “Rapid development of improved data-dependent acquisition strategies”. In: Analytical chemistry 93.14 (2021), pp. 5676–5683.
Closed-loop optimisation of hearing aid parameters, based on subjective user feedback
WP2: Closed-loop hearing aid optimisation
The Problem
466 million people worldwide have disabling hearing loss due to genetic causes, complications at birth, certain infectious diseases, chronic ear infections, the use of particular drugs, exposure to excessive noise, and ageing (source: WHO). A hearing loss impacts an individual’s ability to communicate (effectively) with others, leading e.g. to academic and adjustment problems for children. Exclusion from communication can have a significant impact on everyday life, causing feelings of loneliness, isolation, frustration and dependence. Unaddressed hearing loss poses an annual estimated global cost of $750 billion (12th most common contributor), including health sector costs and productivity.
Modern hearing aids can partially compensate for a hearing loss. However, the effectiveness of a hearing aid is highly dependent on a suitable configuration of the advanced medical device. A state-of-the-art hearing aid requires 10s of different algorithms and 1000s of parameters to compensate for even the simplest hearing loss; each parameter configuration must be tuned to the specific user and condition. The complexity of hearing loss and the HA itself have traditionally called for experts to tune the device in clinical conditions based on audiograms and informal verbal communication with the patient with little control left to the user when leaving the clinic.
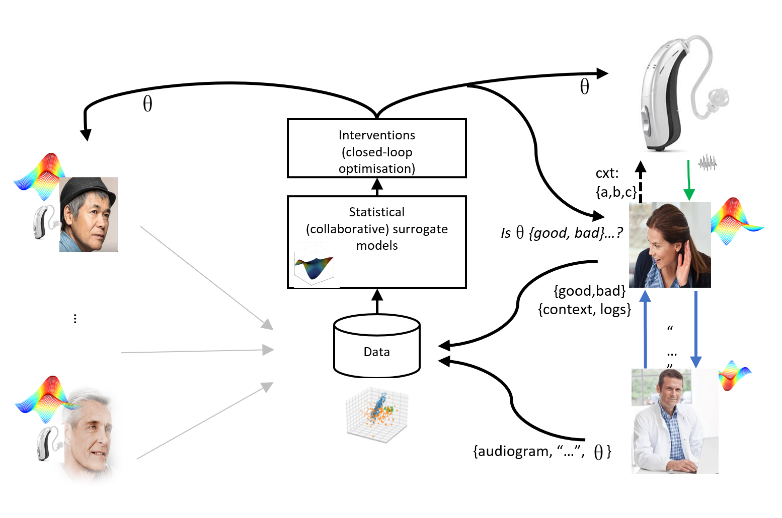
Research Aim:
We will enable real-time and context-dependent optimisation of hearing aid configurations to empower the HA-user and ultimately improve the user/listening experience. By exploiting the availability of population-wide, real-time data streams we will investigate real-time collaborative modelling, intervention and optimisation strategies to provide a significant quality improvement and speed-up in the closed-loop optimisation for both individual and the population of HA-users as a whole.
RQ1 – User Modelling and Analysis:
Models for hearing/hearing loss and choice of configuration are typically formulated and derived based on a single - or a few - patients. By continuously collecting millions of observations from users and clinicians about HA-use and configurations, we will develop scalable non-parametric hierarchical Bayesian models of users, contexts and configurations which enables group-based analysis of preference structures. It will provide predictive models for HA-configurations (e.g. based on user demographic, audiogram and behaviour) and the probabilistic nature of the models will support robust and informed clinical decision-making. Based on the models we will extract and analyse user and preference patterns related to current HA-use, configurations and contexts.
RQ2: Closed-loop collaborative preference elicitation and optimisation:
It is possible to elicit, model and optimise subjective preference in the HA-domain using Bayesian modelling and reinforcement learning (/Bayesian optimisation) in a closed-loop fashion. However, this has been done for individuals independently of other peoples preferences, configurations and context. We will develop new techniques to support multiple feedback loops, multiple timescales and asynchronous feedback to support the collaborative setting with input from multiple users and clinicians at differences timescales and with mixed fidelity. We will develop multi-fidelity/confidence-based optimisation and intervention strategies which accounts for user consistency and reliability in order to avoid suboptimal learning and biases in the closed-loop and collaborative setup. We will develop Bayesian optimisation methods supporting multi-objective and engaging optimisation taking into the intention of the user and costs involved in asking users questions or consulting a clinician. We expect to evaluate the models and strategies in several empirical studies to investigate the effect and consequence of the collaborative and closed-loop optimisation.
Publications:
[1] Salman Mohammadi, Anders Kirk Uhrenholt and Bjørn Sand Jensen, Odd-One-Out Representation Learning, NeurIPS 2020: Workshop on Object Representations for Learning and Reasoning.
[2] Lisa Laux, Marie F.A. Cutiongco, Nikolaj Gadegaard and Bjørn Sand Jensen. Interactive machine learning for fast and robust cell profiling, PLoS ONE, 2020.
Anders Kirk Uhrenholt and Bjørn Sand Jensen, Efficient Bayesian Optimization for Target Vector Estimation, AISTATS 2019.
[3] Anders Kirk Uhrenholt, Valentin Charvet and Bjørn Sand Jensen, Probabilistic Selection of induction point in sparse Gaussian process models, Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence. Uncertainty in Artificial Intelligence. ISSN: 2640-3498. PMLR, Dec. 1, 2021, pp. 1035–1044.
[4] Jasper Kirton-Wingate, Modelling Contextual Preference for Hearing Aid Settings - A Machine Learning Approach, Master of Science by Research, University of Glasgow, 2020, https://theses.gla.ac.uk/81380/
[5] Krasimir Ivanov, Anders Kirk Uhrenholt, Sebastian Stein, Bjørn Sand Jensen. Accelerated GP-based ABC with improved surrogate modelling. Under review at UAI2023. 2023.
[6] Lisa Laux, Marie F. A. Cutiongco, Nikolaj Gadegaard, and Bjørn Sand Jensen. “Interactive machine learning for fast and robust cell profiling”. In: PLOS ONE 15.9 (2020), e0237972.
[7] Richard Sonntag. “A Multi-Task Approach to Hearing Aid Fine-Tuning”. MSci. University of Glasgow, 2021.
[8] Anders Kirk Uhrenholt. “Assumptions and efficiency in Gaussian process modelling”. PhD Thesis. University of Glasgow, 2021. url: https://theses.gla.ac.uk/82442/.
[9] Anders Kirk Uhrenholt and Bjørn Sand Jensen. “Efficient Bayesian Optimization for Target Vector Estimation”. In: Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics. The 22nd International Conference on Artificial Intelligence and Statistics. ISSN: 2640-3498. PMLR, Apr. 11, 2019, pp. 2661–2670.
WP3: Intermittent Control in Data Science
Alberto Álvarez, Henrik Gollee, Roderick Murray-Smith
Variability is an important concept in control systems and data science. It is commonly associated with exploration of the state-space, finding new solutions, and with adaptation and learning. A common way to represent variability is to use stochastic models and added noise, but this has its pitfalls in closed loop data systems as added noise can be propagated around a continuous feedback loop, masking causalities and making identifying system properties more difficult or impossible.
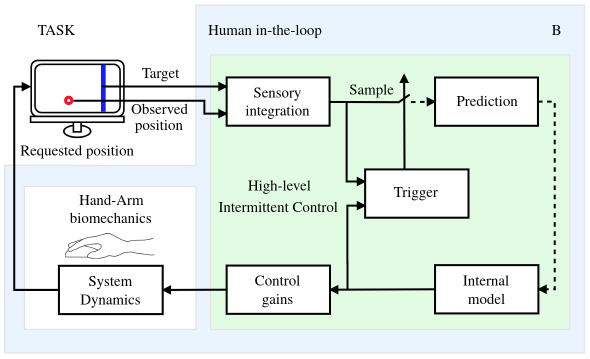
Event-driven control systems naturally introduce variability, e.g. by breaking the continuous feedback loop. This can lead to periods of open-loop exploration of the state-space, making it easier to identify causalities. Intermittent Control (IC), which switches between open and closed-loop regimes, introduces variability through event-driven control while allowing the identification of causal relationships between data sources, and provides clearly defined trigger points for process interactions to take place.
Our IC framework is based on a generalisation of the Model Predictive Control (MPC) approach, using a limited prediction horizon and generalised models for the predictive hold element. In combination with event triggering, this provides a version of MPC which is more suitable for applications in closed loop data science problems.
While the IC framework is based on mechanistic state-space control approaches, it can be extended to provide capabilities for data driven identification and control. This includes machine learning approached for the internal model and for triggering (e.g. Gaussian processes, neural networks and Monte Carlo simulations), causal identification techniques, and data driven adjustment of control gains (e.g. using reinforcement learning).
Main outcomes:
- We have evaluated intermittent control in the context of closed loop system identification and demonstrated that by only using feedback information intermittently, the propagation of noise around the loop is inhibited. In the context of data science, this addresses the problem that an interaction with the system could be propagated through the feedback loop, affecting current and future actions. IC can break this propagating loop through event triggers, allowing adjustment between feedback interaction and propagation of information around the loop.
- Intermittent control has been evaluated in the context of classical Human-Computer Interaction (HCI) tasks. In addition to the overall underlying human control behaviour, intermittent control can also model aspects of human variability in the context of a one-dimensional pointing task [1].
- The Intermittent Control framework has been extended to be fully data-driven, rather than requiring knowledge of the system to be controlled:
- The “Internal model” (i.e. the intermittent hold) and the predictor have been implemented as Gaussian process models (GPs). Data driven identification of these components have been evaluated in various dynamic systems, including a swing-up inverted pendulum model. [2]
- Data-driven methods to identify the “Control gains” have been implemented and evaluated, including reinforcement learning and controller designs based on system identification.
- We have implemented and evaluated an adaptive intermittent control framework which exploits intermittent triggering to address the stability – plasticity dilemma (exploitation vs exploration) in adaptive closed loop systems [3].
The initial implementation of intermittent control was developed in MATLAB (The Mathworks, USA) which makes it accessible to an engineering audience. To allow data scientists access to these algorithms the IC implementation was transferred to Python. This also allows easy integration with the rich eco-system of machine learning tools of the Python environmen. The Python code for the implementation of our intermittent control model is available at https://.....
Publications
[1] Álvarez Martín, J.A., Gollee, H., Müller, J., Murray-Smith, R., 2021. Intermittent Control as a Model of Mouse Movements. ACM Trans. Comput.-Hum. Interact. (TOCHI) 28, 35:1-35:46. https://doi.org/10/gmpchf
[2] Álvarez Martín, J.A., Doublein, T., Gollee, H., Murray-Smith, R., 2022. Understanding the variability of pointing tasks with event-driven intermittent control, in: Proc. MTNS 2022. Presented at the 25th International Symposium on Mathematical Theory of Networks and Systems, Bayreuth, Germany.
[3] Álvarez-Martín, J.A., Gollee, H., Gawthrop, P.J., 2023. Event-driven adaptive intermittent control applied to a rotational pendulum. Proceedings of the Institution of Mechanical Engineers, Part I: Journal of Systems and Control Engineering. https://doi.org/10.1177/09596518221147340
WP3: Closed loop issues in Urban traffic control
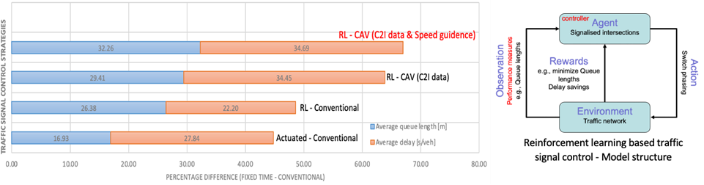
Traffic congestion has been a key urban issue, causing significant costs on economics in many cities worldwide. The traffic signal control system, as an essential tool of smart road principles, can be used to reduce the level of congestion, and thereby transport emissions and fuel consumption in an urban area. The adaptive traffic signal control approach like SCOOT (Hunt et al., 1982) and SCATS (Sims and Dobinson, 1980) has been widely used in real-world traffic network. They are based on an open loop control system that does not consider feedback control in the traffic network. In contrast, a learning-based method like a reinforcement learning (RL) algorithm can be employed to learn from the traffic environment by taking actions (e.g., switch signal phasing) and observing the feedbacks (e.g., queue lengths), enabling researchers and planners to predict the traffic flow more accurately, thereby optimize the traffic signal plan. Due to the new technology improvements, high-tech vehicles (e.g., Connected and Automated Vehicle (CAV)) can communicate with traffic infrastructure, generating important new data. For example, planners can optimize traffic signal control plans based on more accurate current traffic flows and future traffic flow predictions by using data (e.g., speed, location, headway, etc.) sent from CAVs to traffic signal controls. In addition, CAVs can drive more efficiently by receiving updated traffic signal plans, potentially improving an overall network system performance (e.g., number of stops, fuel consumptions, etc). Unfortunately, research on the adoptive traffic signal control with a RL approach and the applications of CAVs in this environment is scarce. In this WP, we use the road intersection as a RL agent while allowing the CAVs to adjust their speed adaptively based on the real-time signal plan received from the controller to examine the closed-loop effects of learning traffic signal controllers and CAVs on the network system performance. Preliminary results show that the proposed method outperforms other dynamic traffic signal control strategies in terms of average vehicle delay and queue length. The sensitivity analysis with different market penetration rates of CAVs and traffic saturation degrees is in the process.
Publications
[3] Michael Sinclair, Saeed Maadi, Qunshan Zhao, Jinyun Hong, and Nick Bailey. “Understanding the Socio-demographic Representation of Tamoco Mobile Phone App Data in Glasgow City Region”. In: GISRUK 2022, Liverpool, UK, 05-08 April. 2022.
[4] Michael Sinclair, Qunshan Zhao, Nick Bailey, Saeed Maadi, and Jinhyun Hong. “Understanding the use of greenspace before and during the COVID-19 pandemic by using mobile phone app data”. In: GIScience (Sept. 2021)
WP4: Adaptation & pro-activeness of Query- & Data-driven Control in Big Data Sys
Fundamentally in WP4, the general idea is that a data system exploits the users’ issued queries to learn the users’ access patterns over the queried data subspaces. The investigated task is to develop ML models that can identify the most interested data regions by advising the users during data exploration process. Such models take users’ feedback into account, which is represented as the user tendency to issue/execute queries over the recommended data regions.
Moreover, exploiting the aggregation results of users’ executed queries, we developed ML models which can explain the outcome of (aggregate) queries to users by advising them how the predicted outcomes vary around queried data regions. Such models take the user feedback, as the user intention to ask for detailed explanations around regions of interest and explore areas over the data subspaces where an explanation of the data distribution might be requested in the future.
Furtherore, under the context of the query-driven learning, we developed ML models which can recommend to users the next query to be executed based on the users’ past sequential access patterns. The user feedback in this context is represented by the user acceptance/rejection of the next queries to be executed.
In all the research activities in WP4, we distinguish two axes related to the closed-loop data science:
- Interaction with humans/end-users/analytics applications: In our problem formulations we considered human interaction data, either implicit (via queries to be executed) or explicit (via identifying interested regions for further exploration or explanation of the underlying data distribution), as the feedback to the system. Then, the system/models adapt the decision-making according to this feedback considering criteria quantified by the popularity of identified regions and explainability of the outcomes of the executed queries.
- Uncertainty in recommender systems: WP4 investigated the diversification and uncertainty in recommender systems from a theoretical perspective. Our work investigated the diversification in recommender systems by proposing a strategy to find balanced hyperparameters to minimize the effect of popularity bias due to closed-loop feedback effects.
In more details, the WP4 activities can be grouped into the following three sub-work packages.
Sub WP4.1: We investigated ML and Computational Intelligence models to learn and identify interested data regions for end-users/analysts helping them to explore data subspaces for predictive analytics tasks. The research area is under the umbrella of interactive-data mining inspecting m-d data regions summarized by simple statistics. The values of these statistic (e.g., region-population size, order moments) are used to classify the region’s interestingness. Example data mining applications of this initiative include identifications of geographic regions with crime index more than a national average, or areas where sensors readings can go beyond a threshold are harmful/pollution level, or identification of landmarks based on tracking data, or finding the top-k regions of interest.
Notably, in this direction, we studied the reverse problem, i.e., analysts provide a cut-off value for a statistic of interest and in turn our system efficiently identifies and suggests regions whose predicted statistic exceeds a given cut-off value (according to user’s needs). We proposed and developed a Surrogate Region Finder system, coined SuRF, which leveraged historical region evaluations based on users’ acceptances (feedback) to train surrogate models. The surrogate models learn to approximate the distribution of the statistic of interest as long as users accept the suggestions to execute queries for further exploration. SuRF adopts evolutionary multi-modal optimization (Glowworm Swarm Optimization) to identify regions of interest regardless of data size and dimensionality.
Sub WP4.2: We studied and developed ML models that can support query-driven aggregate analytics explanations. Specifically, in this sub-work package, we developed models to accommodate the exploration of m-d data spaces involving aggregate queries with selection operators, i.e., range or equality predicates, defining data subspaces. The challenge is that the query results are scalars and convey limited information and explainability about the queried subspaces for exploratory analysis. Hence, analysts have no way of identifying how these results are derived or how they change w.r.t query parameter values. Our developed system aids analysts to explore and understand data subspaces by explaining query results using regression functions. The developed explanation functions are estimated using past executed queries, which have been suggested by the system to the analysts. Hence, the analysts’ accepted & executed queries (feedback) provide a coarse-grained overview of the underlying aggregate function to be estimated. Finally, explanations for future/unseen queries are delivered without accessing the data and can suggest users to further explore the queried data subspaces.
Sub WP4.3: In this sub-work package, we firstly focused on the query recommendation problem using Multi-Armed Bandits (MABs), and then we further investigated how this RL paradigm can be applied to a field outwith of the query recommendation (specifically, in dynamic pricing policy mechanism, as mentioned later in this report). Specifically, in this context, the key objectives in query recommendation and prediction in closed-loop interactive learning settings are: online information gathering and exploratory analytics tasks. The problem we were challenged is predicting and recommending to the analytics the next-query to be executed over a stochastic MAB framework with countably many arms (next-queries to be recommended). We developed a MAB system that sequentially chooses arms based on the likelihood of a query being recommended w.r.t. currently and past executed queries. In this context, the feedback is captured in an online fashion by user acceptance/rejection of the recommended queries, which is used to further refine the prediction accuracy of the MAB algorithm. Hence, the system develops incrementally a query selection strategy based on the maximum utility of the arms.
We have been experimenting with using a real online literature discovery service log file showcasing that the selection strategy improves the cumulative regret substantially w.r.t. commonly used MAB selection strategies. First publication was the 2021 ACML paper on subset selection of queries for next-query recommendation and the second publication was the 2022 SIGIR-ICTIR paper on balancing diversity-relevance in recommendations. One publication is under review in SDM 2023 where we proposed to improve transformer-based models for query recommendation by incorporating immediate user feedback.
WP 4 References
- Long, Q., Kolomvatsos, K. and Anagnostopoulos, C. (2022) Knowledge reuse in edge computing environments. Journal of Network and Computer Applications, 206, 103466.
- Puthiya Parambath, S. A., Liu, S., Anagnostopoulos, C. , Murray-Smith, R. and Ounis, I. (2022) Parameter Tuning of Reranking-based Diversification Algorithms using Total Curvature Analysis. In: 8th ACM SIGIR International Conference on the Theory of Information Retrieval (ICTIR 2022), Madrid, Spain, 11-12 July 2022.
- Kolomvatsos, K., Anagnostopoulos, C., Koziri, M. and Loukopoulos, T. (2022) Proactive & time-optimized data synopsis management at the edge. IEEE Transactions on Knowledge and Data Engineering, 34(7), pp. 3478-3490.
- Puthiya Parambath, S., Anagnostopoulos, C. , Murray-Smith, R. , MacAvaney, S. and Zervas, E. (2021) Max-Utility Based Arm Selection Strategy for Sequential Query Recommendations. In: 13th Asian Conference on Machine Learning (ACML 2021), 17-19 Nov 2021, pp. 564-579.
- Anagnostopoulos, C. and Kolomvatsos, K. (2020) Predictive intelligence of reliable analytics in distributed computing environments. Applied Intelligence, 50, pp. 3219-3238.
- Savva, F., Anagnostopoulos, C. , Triantafillou, P. and Kolomvatsos, K. (2020) Large-scale data exploration using explanatory regression functions. ACM Transactions on Knowledge Discovery from Data, 14(6), 76.
- Savva, F., Anagnostopoulos, C. and Triantafillou, P. (2020) Adaptive learning of aggregate analytics under dynamic workloads. Future Generation Computer Systems, 109, pp. 317-330.
- Anagnostopoulos, C. (2020) Edge-centric inferential modeling & analytics. Journal of Network and Computer Applications, 164, 102696.
- Savva, F., Anagnostopoulos, C. and Triantafillou, P. (2020) SuRF: Identification of Interesting Data Regions with Surrogate Models. In: 36th IEEE International Conference on Data Engineering (IEEE ICDE), Dallas, TX, USA, 20-24 April 2020, pp. 1321-1332.
- Savva, F., Anagnostopoulos, C. and Triantafillou, P. (2020) Aggregate Query Prediction under Dynamic Workloads. In: 2019 IEEE International Conference on Big Data (IEEE BigData 2019), Los Angeles, CA, USA, 09-12 Dec 2019, pp. 671-676.
- Anagnostopoulos, C. and Triantafillou, P. (2020) Large-scale predictive modeling and analytics through regression queries in data management systems. International Journal of Data Science and Analytics, 9(1), pp. 17-55.
- Savva, F., Anagnostopoulos, C. and Triantafillou, P. (2019) Explaining Aggregates for Exploratory Analytics. In: IEEE Big Data 2018, Seattle, WA, USA, 10-13 Dec 2018, pp. 478-487.
Academic Staff
Dr Chaitanya Kaul (Computing Science)
Dr Catherine Higham (Computing Science)
Erlend Frayling (Computing Science)
Dr. Ke Yuan (Computing Science)
Funded Projects
Vacancies
Currently no vacancies.